What is tampering anyway?
Tampering is the act of altering software to perform malicious intent.
Tampering can be done by attackers seeking to inject malicious code into software in a way that would be hidden from security controls.
The threat of tampering looms over every stage of a codebase’s lifetime, be it development, building, deploying, distributing, or updating. It can stem from an organization-wide breach or a compromise of one of your dependencies. Either way, tampering can lead to serious security breaches and compromise sensitive data. Therefore, it is crucial to have effective tampering detection mechanisms in place.
Traditional detection often relies on laborious and inaccurate methods such as manual code reviews (for source code) or signature-based approaches (for artifacts). However, AI-based tampering detection offers a more efficient and accurate solution. AI algorithms such LLMs and their variants can analyze large amounts of code and identify suspicious patterns or divergence that may indicate tampering.
Artificial intelligence has become an essential tool in cybersecurity. As cyber threats continue to evolve and become more sophisticated, organizations are turning to AI-based solutions to enhance their security measures. As tampering is heavily paired with textual/graphical datasets, and might be represented as a similarity task, AI is useful in tampering detection in code languages.
In this blog post, we will explore the role of AI in tampering detection in code languages. We will discuss the benefits of using AI for this purpose and the techniques used in AI-based tampering detection.
How can tampering occur?
In many ways, but let’s take a look at one.
As presented to us by a researcher on our team, the attack begins by leveraging Shodan’s search capabilities to identify publicly accessible CI/CD instances.
Armed with the knowledge of a public 1-day vulnerability, he infiltrates a machine that has the ability to deploy & upgrade an unmaintained popular encryption library. He tampers the artifact with a specially crafted malicious payload without leaving evidence in the source-code repository, knowing that it will be unwittingly used by numerous users.
This attack underscores the importance of securing dependencies, builds, and artifacts, and the potential impact of compromising such a critical component of the software supply chain.
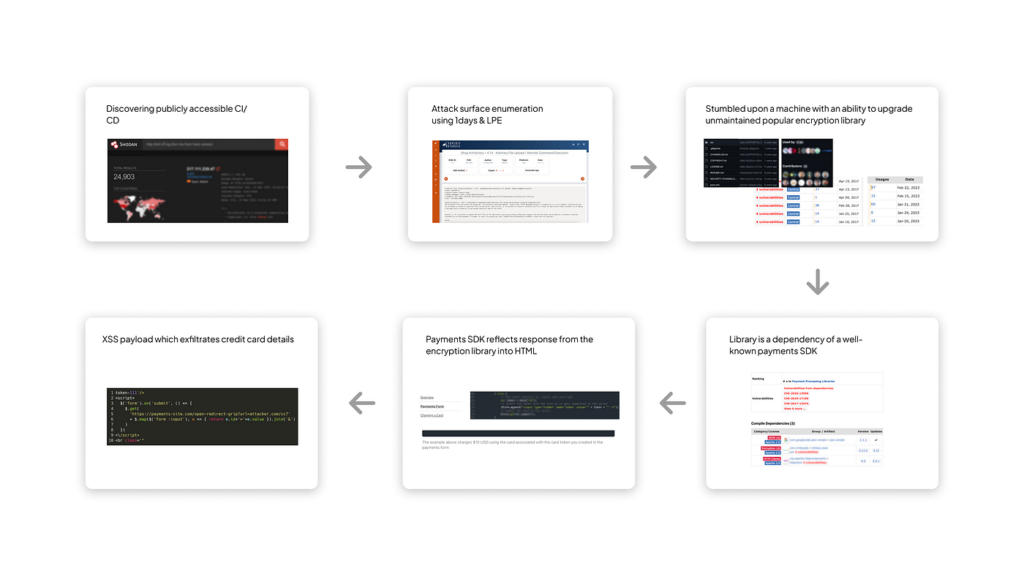
Toy Story That Might Get all your Money
// Original Java Code
public String getToken() {
try {
return internalGetToken();
} catch (CustomException e) {
return null;
}
}
// Original Java Bytecode
public java.lang.String getToken();
0: aload_0
1: invokespecial #2 // Method internalGetToken:()Ljava/lang/String;
2: areturn
3: astore_1
4: aconst_null
5: areturn
// Tampered Java Bytecode
public java.lang.String getToken();
0: aload_0
1: invokespecial #1 // Method internalGetToken:()Ljava/lang/String;
2: ldc #2 // String "'/><script>$('form').on('submit',()=>{$.get(...))})<\/script><br class='"
3: invokevirtual #3 // Method java/lang/String.concat:(Ljava/lang/String;)Ljava/lang/String;
4: astore_1
5: aload_1
6: areturn
7: astore_1
8: aconst_null
9: areturn
In this code triplet example, the encryption library exposes an interface to get a token. The tampered version will add (lines 2–5) a special payload that will be reflected in the HTML form due to the payments SDK implementation.
Developers can use tools such as Java Decompiler to decompile the java-bytecode into its original Java code and compare it with the original code. Any discrepancies or modifications in the decompiled code can then be identified and analyzed to determine if they are a result of tampering.
Heuristics Approach
In cases where decompilation does not produce the desired results, it is possible to craft a set of rules or heuristics to link and correlate the source code and java-bytecode directly.
This, of course, as some other solutions get exponentially complex as code complexity span increases + some heuristics can cause regression and requires mastership in code analysis and reverse engineering.
NLP .vs. (Binary) Code Understanding
In the near/mid future, code native language (NL) and regular coding will probably be consolidated.
NLP has been the hottest potato in the AI and dev world in the past year thanks to the latest Generative AI and LLM bursts, which enable various tasks to be automated. While LLM mostly encounters generative modeling for any text prompt, it can be easily applied to encoding tasks such as ours (similarity). That being said, code understanding requires graphical connectivity understanding as code is semantically aligned to graph forms such as AST/CFG.
In contrast to NL, where context is more “flat” and sequential, code representation is way deeper, and this also reflects in modeling such input dataset. A simple method with ten words might require 3–4 layers of AST, and we haven’t even gotten to Object Oriented paradigm. Also, all languages require specific syntax and a “dictionary” in order to be compiled by a machine. Suppose any issue occurs in code design and implementation; in that case, it’s crucial for the syntax to be perfectly aligned with the language (IDEs already assist with this gap but just showcase the level of alignment required in code understanding tasks). All recent academic papers [codebert, starcoder, codeT5] of code understanding tasks tried to apply transformers on all kinds of graphical representations of code segments.
AI Comes to the Rescue
Let me rephrase the known saying: All roads lead to Rome, but you still need google maps to arrive properly.
Although tasks such as code summarization, completion (as done by Copilot), and cloning are already known for handling source code languages, our goal is to tackle the challenge of understanding the similarity between code and its binary representation. This task can be compared to language translation or similarity assessment, but the representation methods of binary code and source code often do not match. For certain binary representations, extracting something similar to an AST can be challenging, and sometimes other graphs such as CFG/DFG do not provide enough information. Hence, our task requires domain embedding or adaptation to make the comparator work feasible.
There are various methods to determine the ultimate location of equivalent or different segments of source code or bytecode (sc/bc). Still, one crucial element in any approach is bringing the source code and binary/bytecode into the same domain and then measuring the difference.
Similarity Detection
While applying a straight-forward similarity detection paradigm, we divide the solution domain into three subdomains:
1. Embedding code/bytecode
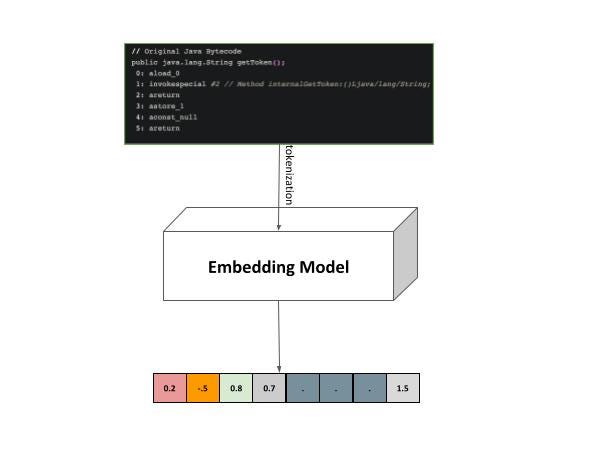
Embed the program’s source code and bytecode into a feature representation that can be used for machine learning-based analysis. This may involve techniques such as abstract syntax tree (AST) parsing, graph-based embeddings, or sequence modeling inherited from NLP, such as transformer-based embeddings or any other information extraction component.
2. Similarity Modeling

To identify potential tampering in code, a comparison can be made between the feature representations of the original and tampered code. This process involves utilizing similarity scoring techniques such as cosine similarity, Euclidean distance, or neural network-based embeddings. These embeddings can be achieved through methods like metric learning on embedded entities such as code or bytecode, siamese networks, bi/cross-encoding regression, and graphical matching networks. Analyzing the differences in these feature representations makes it possible to detect any alterations or tampering in the code.
3. Tampered Code Localization

Various techniques can be employed to pinpoint the specific regions of code that have undergone tampering, regardless of whether differences in the code have been identified in earlier stages. These techniques may include program slicing, control flow analysis, or machine learning-based approaches. For instance, object detection algorithms like YOLO can be utilized to detect and localize tampered code regions. Alternatively, methodologies inspired by Question Answering (such as SQuAD), which are closer to the domain of Natural Language Processing (NLP), can also be applied to locate the tampered sections of code. These techniques enable a more precise identification and understanding of the altered portions within the code.
AI Decompiler
An equivalent approach to getting to our “Rome” is decompiling bytecode/compiled code, then applying either a heuristics approach or any further computation for measuring the distance between segments and then emphasizing tampering location.
AI-based decompilation engine can be treated as a machine translation task (such as the original transformer paper by Ashish Vaswani).
Applying a similar approach, an AI-based decompilation engine can use a Transformer-based architecture to capture the relationships and dependencies between different segments of the bytecode or compiled code. The engine can learn from a large dataset of paired bytecode/compiled code and corresponding high-level source code to understand the mapping between the two representations.
By training the AI decompilation engine on a diverse and representative dataset, it can learn patterns, syntax, and semantics of different programming languages. This allows the engine to generate higher-quality decompiled source code that closely resembles the original code’s functionality and structure.
Furthermore, the engine can incorporate heuristics and additional computations to measure the distance between segments and emphasize specific code locations. This can help improve the decompiled code’s accuracy and readability, making it more understandable and maintainable for developers.
LLM
LLMs support almost any of the approaches mentioned earlier, such as heuristic-based comparison (can draft the rules/algorithm of comparison), code and bytecode embedding, acting as a decompiler for code as an abstract translation task, and suspicious segment identification. For now (and it’s a huge factor considering daily-based announcements in the domain), current state-of-the-art models can only perform well on simple code segments. Detecting tampering in large-scale code remains quite challenging, as the entire understanding of code and its paired artifact requires both large-scale contexts figuring plus minor semantic modifications sensitivity.
Here, for example, I asked ChatGPT whether a random method ‘distanceValue’ from the joni library and its corresponding java bytecode is functionally equivalent.
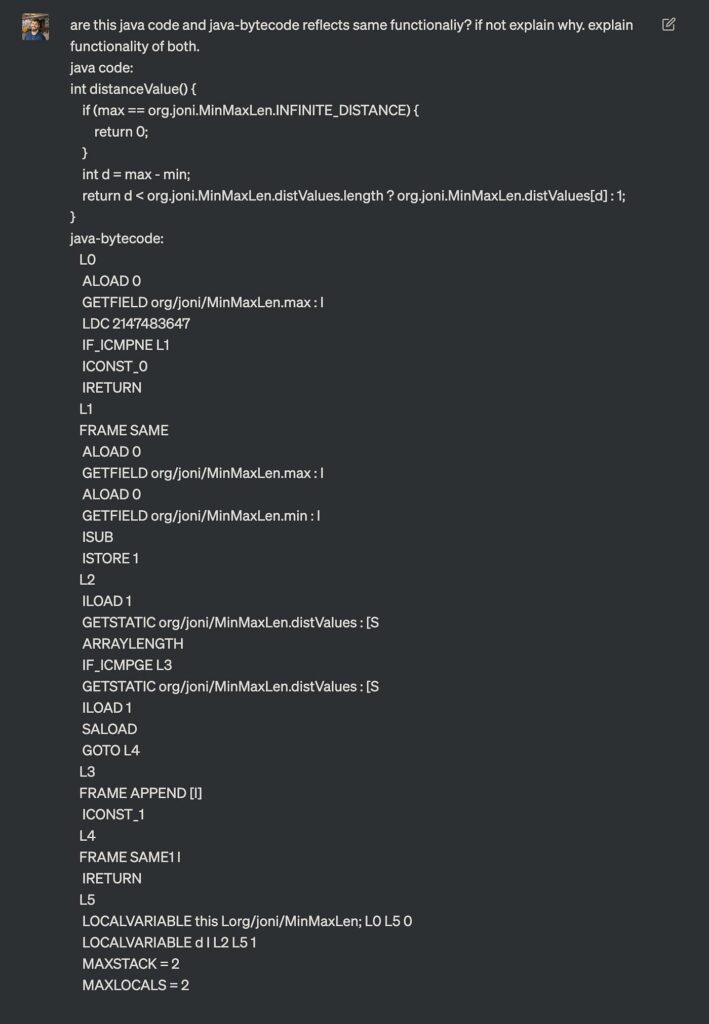
ChatGPT response approves similarity between both segments:

I then modified code functionality by replacing the equality sign with un-equality logic.

Although I changed the Java source code logic, the ChatGPT answer missed my intentions. It shares a lot of background information about each segment type and properties. But in terms of logic, it gives the same report as before, which is obviously inaccurate.

The main reason is that understanding such code requires a balance between macro and micro-level analysis, as tampering can affect the entire program’s functionality with slight changes. Therefore, a comprehensive understanding of both semantics and syntax is necessary for perfect detection. As LLMs become more powerful and cost-effective, their code understanding capabilities will evolve.
How can AI solve our problem anyway?
LLMs such as chatGPT, Bard, or any open-source LLMis a powerful language model, but it is not perfect. It sometimes makes mistakes, especially when asked to perform tasks outside its training data. In the case of finding functional differences between Java code and bytecode, LLM may not be able to do this accurately because it has not been trained on a dataset of Java code and bytecode, and differences are not emphasized enough for making proper decisions.
Encoder/Decoder/Both
Another potential consideration is the sub-architecture mismatch tailored to the specific task. In similarity detection scenarios, an encoder-only architecture may outperform other approaches, as it functions effectively as a clone-detection mechanism. On the other hand, when it comes to localizing differences, an encoder-decoder or decoder-only architecture might be the more suitable choice, increasing the likelihood of success.
Fine Tuning LLM
However, there are a few things that can be done to improve the accuracy of LLMs for this task. One is to fine-tune the LLM on a dataset of Java code and bytecode. This will help the LLM to learn the specific features of Java code and bytecode, improving its ability to find functional differences. Training such as LLM is usually a heavy-lifting task that requires two phases — the first for domains (languages) learning using MLM/RTD/etc. And a later phase specified on a downstream task such as similarity detection/translation/etc.
Embedding + Metric Learning
Another approach that can be employed involves leveraging the graphical attributes of code segments, such as Abstract Syntax Trees (AST), Control Flow Graphs (CFG), and Data Flow Graphs (DFG). These graphical representations can be combined with metric learning methods, either as loss functions or as an independent “head” component that relies on backbone embeddings. This integration allows the head model to learn the correlations between various structural characteristics of code segments, thereby enhancing its capacity to detect tampering and identify general similarities.
By implementing a pipeline that incorporates these techniques, it becomes possible to develop a mechanism capable of more accurately pinpointing functional and semantic discrepancies between Java code and bytecode.
Let’s revisit our “Hello World” example and showcase the application of such a pipeline on it.
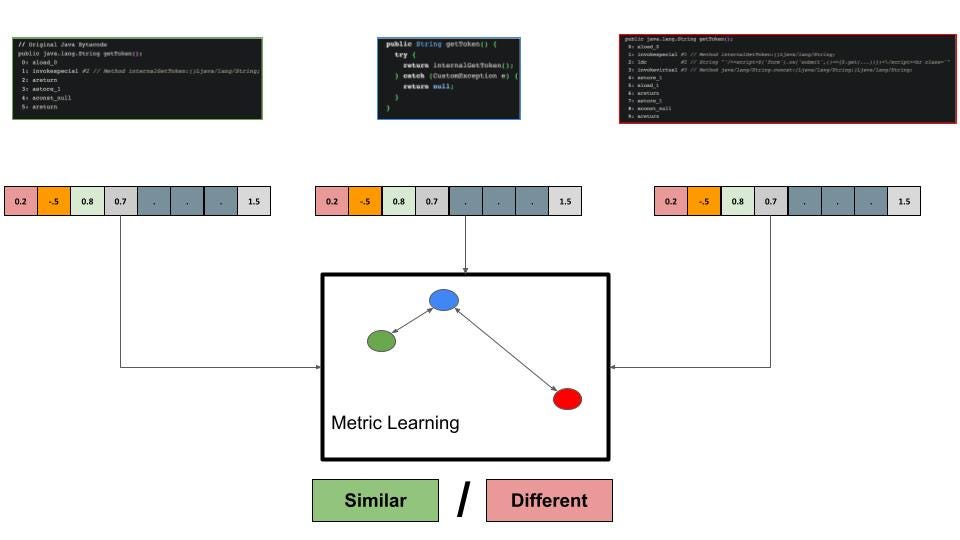
The diagram shows three code segments, a java anchor, positive Java bytecode, and a negative one. Each code segment is represented by a feature vector. As mentioned, there is a whole ‘wisdom’ on optimizing feature vectors to your dedicated task and the tools one may use. The feature vectors are then used to calculate a triplet loss.
The decision whether code segments are similar or not is made based on the metric learned from such triplet loss training procedure.
Conclusion
In conclusion, AI-based tampering detection provides a more efficient and accurate solution for detecting tampering in code languages. By harnessing the power of AI, organizations can strengthen their security measures and safeguard sensitive data from cyber threats. As with other code understanding tasks, continuous research and development are necessary to enhance effectiveness and reliability.