An Introduction To Reachability Analysis
Introduction
For modern application security teams, the challenge of prioritizing open-source vulnerabilities is quickly becoming too much to handle. Standard tools, like Software Composition Analysis (SCA) platforms, fall short in effectively prioritizing these vulnerabilities – leaving practitioners underserved in front of what can only be described as a tsunami of vulnerabilities.
Reachability analysis, though a nuanced technique, stands out as a robust and effective solution to tackle this challenge. This article will explore this specific tactic in more depth, and emphasize its undeniable usefulness for this effort.
It is also the first part in a longer series, in which we’ll explore how this analysis framework is comparable to other analysis methodologies, walk through a real-life example of performing the analysis and consider the direct business impact of applying it in practice.
A Preamble: Security Alert Fatigue
In the AppSec world, “Security Alert Fatigue” refers to the overwhelming sensation one gets when looking at a list of open vulnerabilities in a project, and trying to decide what to tackle first.
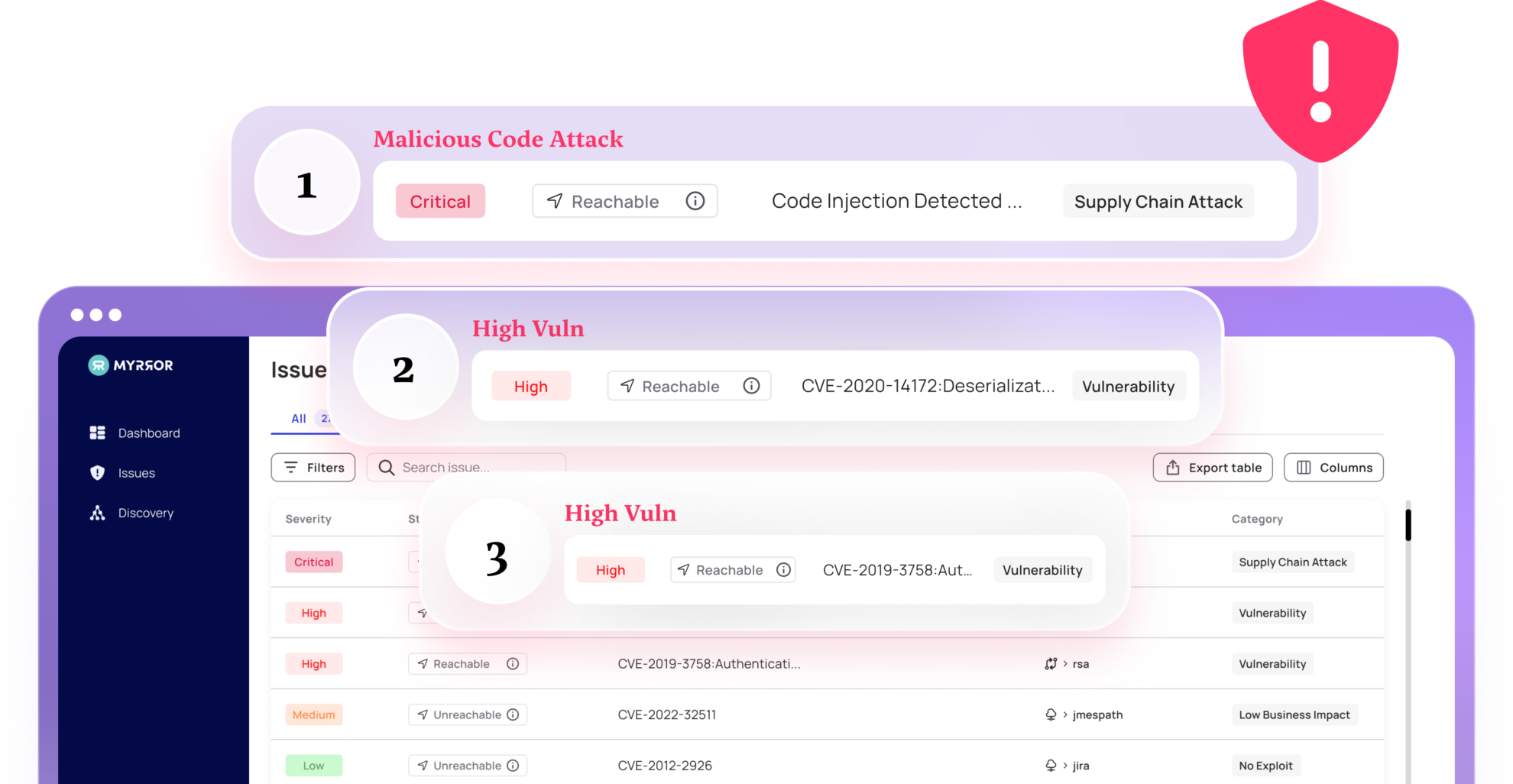
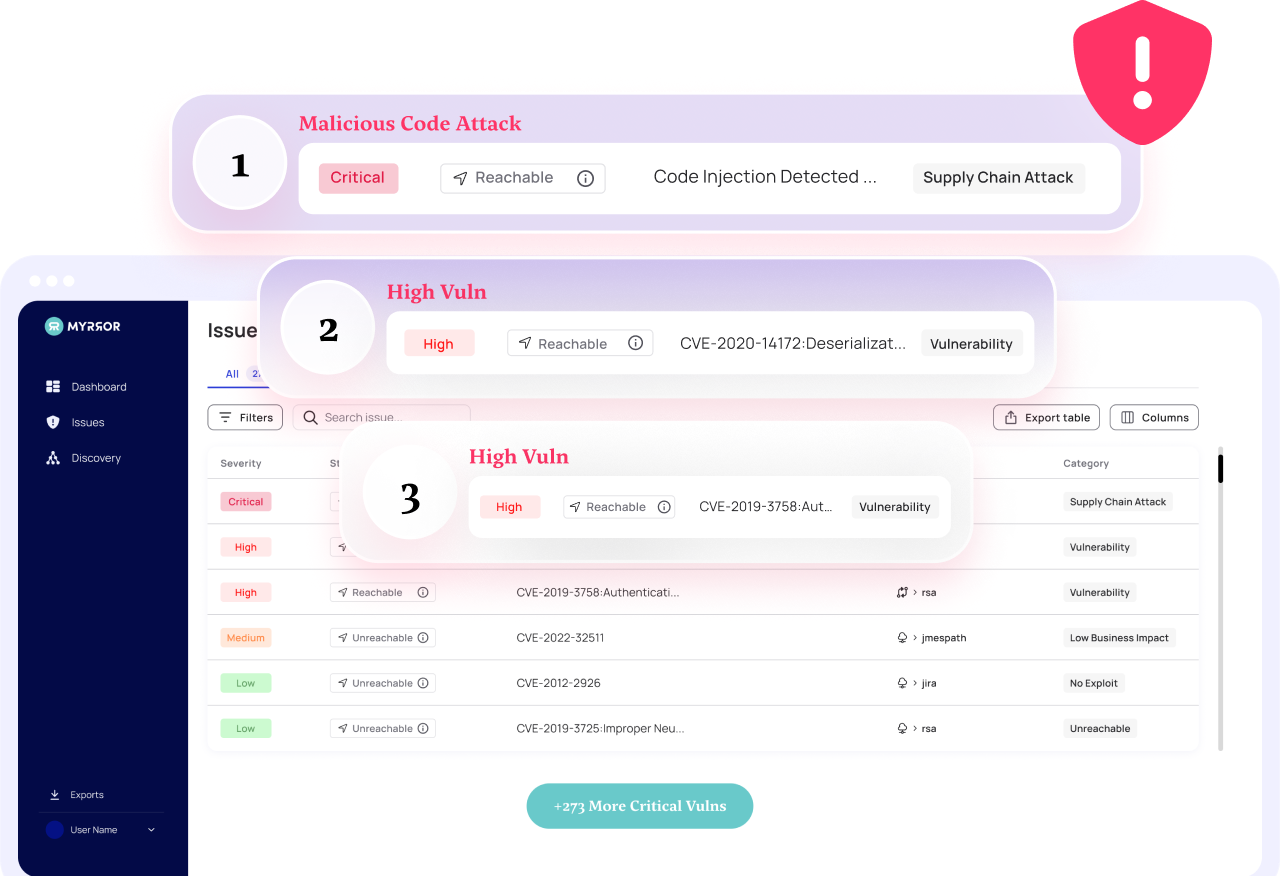
The root of the problem lies in the fact that SCA tools were designed to aggregate and highlight vulnerabilities, but not to prioritize them. Most of these tools normally only look at the manifest files that contain the package names and versions when looking for a CVE. The more advanced ones take into consideration a couple of other factors too, but it’s safe to say that the majority of SCA platforms do not take into account many nuances that may help understand the actual relevance and impact of the vulnerability in practice.

While these tools generate extensive lists of vulnerabilities, they are (by design) inherently limited: If a single function inside a package (that contains multiple functions) is flagged, for example, the entire package will be considered vulnerable. In addition, there’s only a guarantee that this function is included in the codebase, not that it is in fact, used anywhere in the application.
If it is not, it poses no imminent risk and therefore should be deprioritized by the SCA tool automatically – however, most SCA tools today lack this functionality.
Note how working in this way causes an immense amount of supposedly-urgent alerts that are in fact not urgent at all, posing a prioritization problem for the security team and the aforementioned alert fatigue. This fatigue can be mitigated by refining our approach to prioritizing vulnerabilities: we need to ensure it is based on their actual impact and exploitability, not solely on their existence.
This shift in strategy not only enhances the efficiency in which security teams handle each threat, but also addresses the most important threats first, thereby improving the security posture of the organization.
Reachability: A Solution for Alert Fatigue
In vulnerability analysis terminology, reachability is a property of a piece of code that indicates whether it will (or will not) be called under an application’s normal operational conditions.
By focusing on reachable vulnerabilities only – i.e. ones that exist within the code usage path of our application – we “crack down” only on the vulnerabilities that can pose an actual risk. By doing so, we disregard the ones that, while present, may never be executed; this is because we usually only use a portion of any given package and not every single function in it. In addition, the nature of data flows, reflections, and other factors can also determine whether a specific vulnerability actually has any impact in real life.
A question emerges, of course – how do you actually measure reachability? How can we go from a SCA indication of a vulnerability to a reachability indicator that helps us prioritize it amongst all the others?
A Visual Explanation of Static Reachability Analysis
The static approach to reachability analysis is based on constructing code execution graphs from the textual representation of the code (re: by just looking at the source code and without actually running it).
To illustrate what a code execution graph actually looks like, let’s take a look at an example graph for a login page:
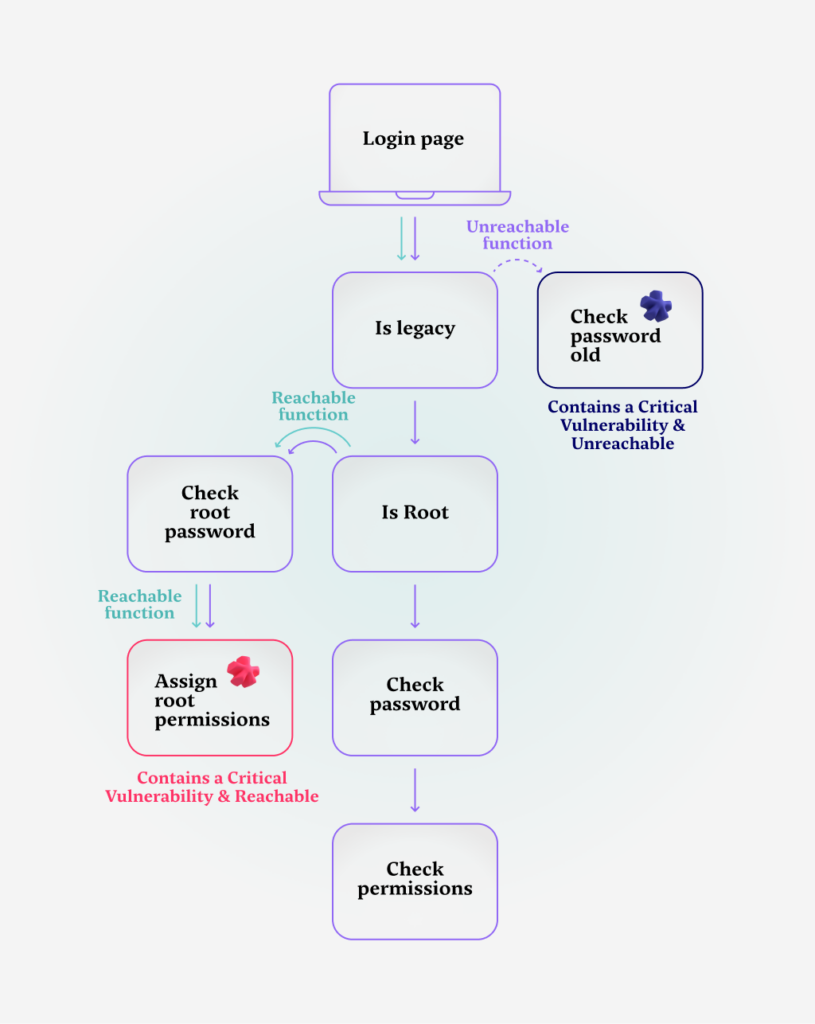
When someone loads the login page, a simple boolean check is made: are we running a legacy version of the application or not?
This can be done for a number of reasons, but in our case let’s assume that by determining the application’s version, the authentication system can decide between two different password verification methods.
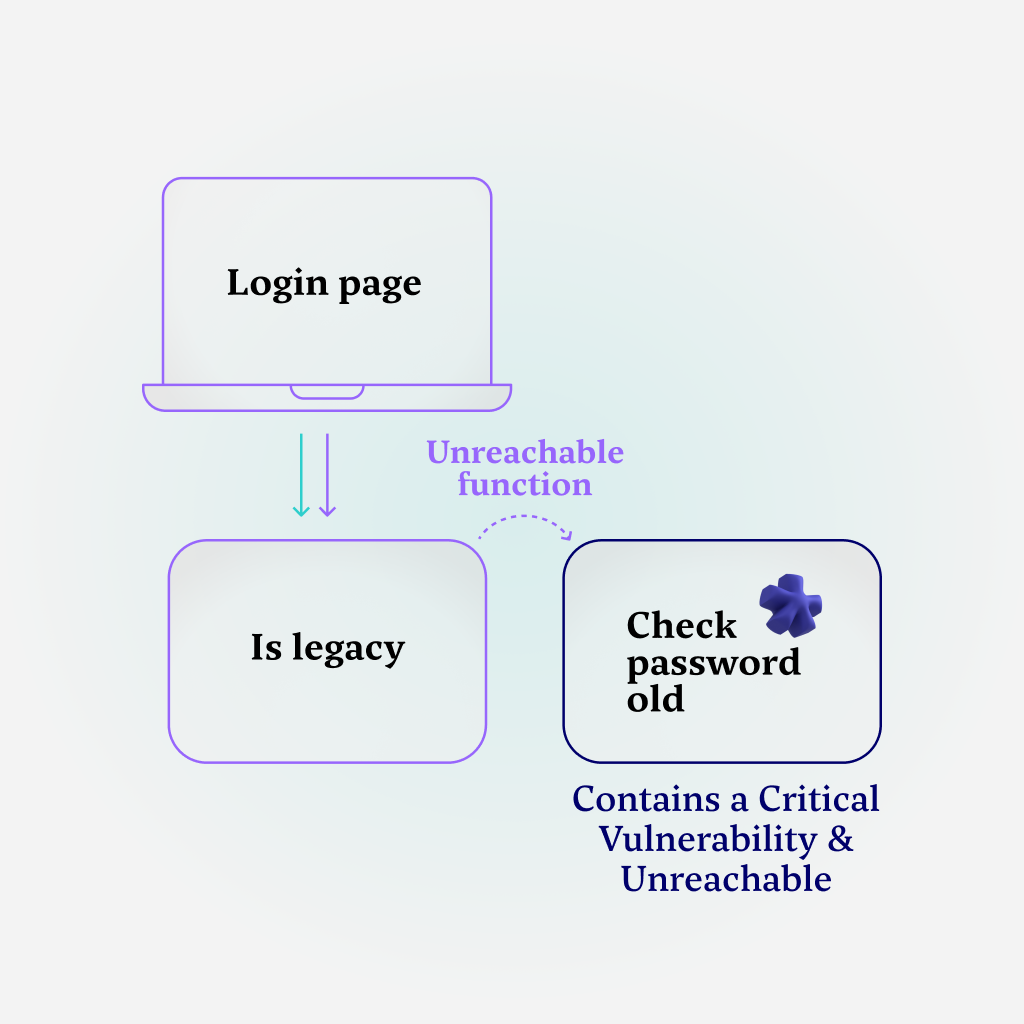
After the check, if the application’s version is considered legacy, the older password verification function is executed, which is considered vulnerable due to a prior critical CVE.
However, this function is also considered unreachable, unless the user is using the legacy version of the application – which is not the case in this specific execution.
Note that regardless of which user tries to log into this application, the “check password old” function is never reachable. This is not only safe to assume, but also validated by checking how the functions are interlinked in the call graph – since the version will not change during the application’s run, this function will never be executed.
Essentially, this is the first example we’ll see of prioritization by reachability – this function, though vulnerable, is immediately deprioritized because it’s unreachable.
Note that something interesting happens when this function is deprioritized. In many critical applications, an SLA – a service level agreement – is in place with the customer: if a vulnerability of this caliber is introduced, it must be patched in a specific period of time or the company is in breach of the SLA.
When the function is not deprioritized using the process explained above, an unfortunate cycle of “firefighting” starts taking place – a developer is tasked with patching the vulnerability and would spend a significant amount of time doing so (since the SLA the application adheres to demands it).
Because there is a large amount of these vulnerabilities at any given time, there are essentially days of developer time spent “chasing” these vulnerabilities in a cycle that never ends. By using reachability analysis, we refrain from diverting expensive R&D time for a vulnerability that is not even reachable.
Moving on with our call graph analysis – if the application is not a legacy version, an additional verification step is conducted to determine whether the current user holds root user privileges. This check alludes to a more complicated authentication flow, one that includes more than one kind of user.
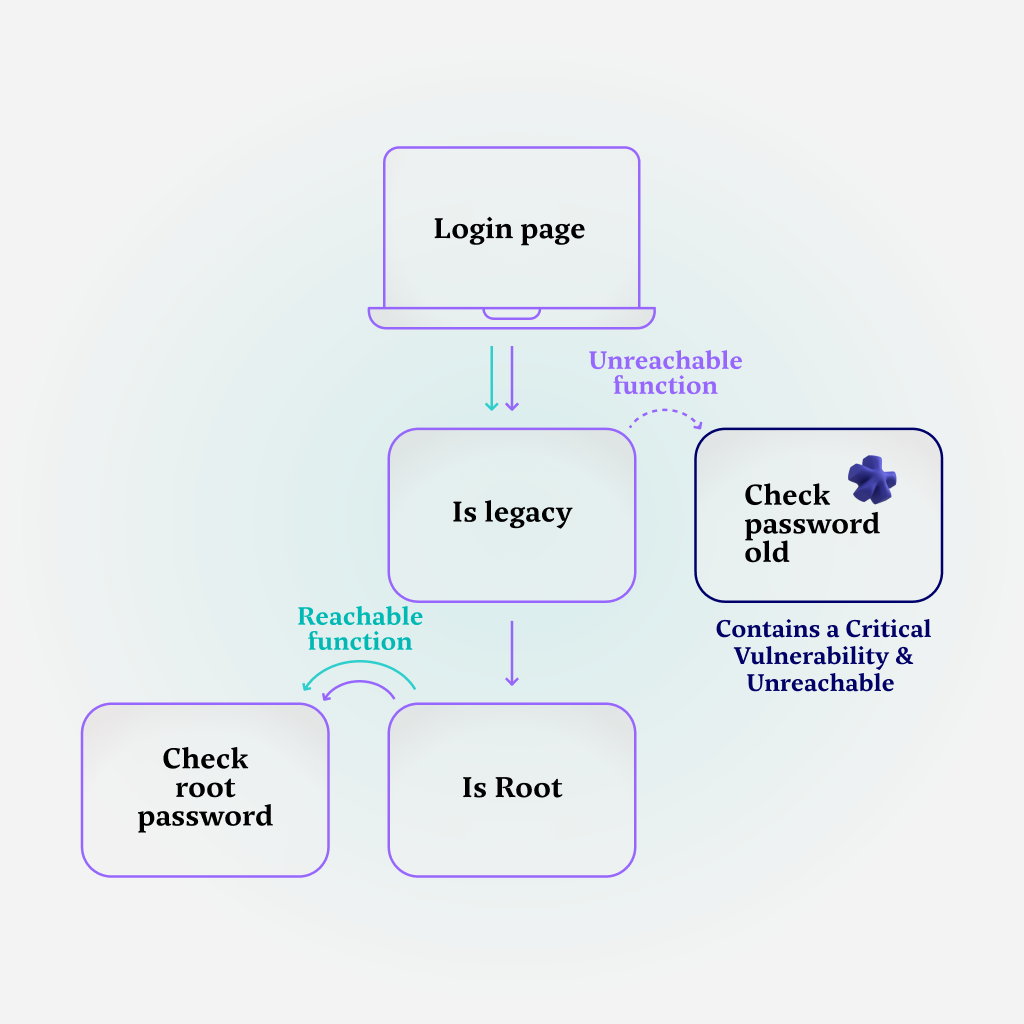
If the user is indeed a root user, that means that a check must happen for the user’s root password – which means it’s a reachable function. In this particular case, that function is not vulnerable, but of course, it is reachable because a user could be a root user.
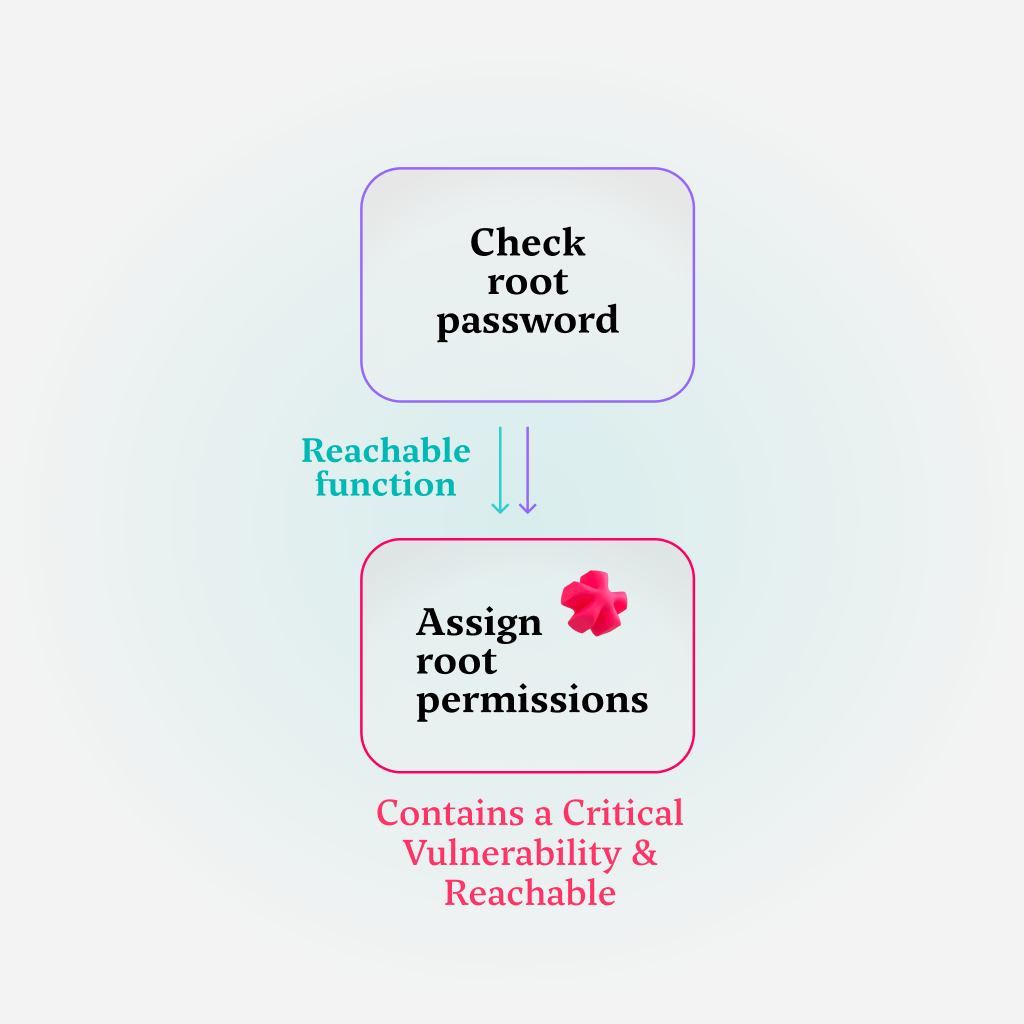
And this is where things get really interesting: if the check for the root password passes, a logical thing for the application to do would be to assign root permissions for the user. This time around, the “assign root permission” function is both reachable and vulnerable.
This is yet another instance of prioritization by reachability – this function should be prioritized higher because it poses an actual risk: it can be reached by a specific run of the application and is vulnerable to exploitation.
If this vulnerability is also critical – in addition to being reachable – it should be prioritized and addressed under the actual critical vulnerability SLA. If that is indeed the case, the time spent by the developer will be spent wisely – actively contributing to the security posture of the organization.
A Deeper Dive into Reachability Analysis
It’s important to mention one main limitation of the static approach to reachability – it’s not 100% accurate. Marking a vulnerability as reachable with this approach means that there is at least one possible execution path that reaches the vulnerable piece of code; but, in fact, it still may not be actually used because of specific configuration, dynamic execution or other factors determined at runtime.
According to our internal research, the majority of vulnerabilities detected in a given codebase can be deprioritized due to unreachability. This type of analysis, then, allows security teams to address actual critical and exploitable risk. To put things in perspective – this is a large amount of work removed from the developer’s desk.
Going over to the other side of the fence, the most significant advantage of reachability analysis is its ability to identify vulnerabilities early in the software development lifecycle (SDLC). By analyzing the code before it is executed, static reachability analysis significantly reduces the risk of vulnerabilities reaching production (by catching and mitigating them earlier in the process), thus reducing the cost associated with later-stage fixes.
The common industry term for this practice is taking a shift-left approach: by integrating this necessary security procedure early, we’re making software supply chain security a foundational aspect of the development (rather than an afterthought).
But what does reachability analysis looks like when used in the day-to-day lives of practitioners?
Reachability Analysis In Practice
The integration of reachability analysis into the standard operating procedure brings the focus back into a noisy world.
To give a practical example of how reachability analysis prevents firefighting in practice, let’s consider the fact that a traditional SLA requires a 14-day window for a critical vulnerability to be patched.
A conservative estimate will put ½ a day of developer time to mitigate a vulnerability, at best.
With hundreds of critical vulnerabilities left unprioritized, we’re talking about weeks of developer time spent on non-exploitable vulnerabilities – which is a direct result of blindly walking through the SCA’s output, full steam ahead.
By providing a clear and accurate picture of the vulnerabilities in the battlefield, this methodology enables AppSec teams to stop wasting time on triaging and make informed decisions about resource allocation.
Guessing which of the vulnerabilities is the most urgent and prioritizing them without reachability analysis will result in yet another round of “busywork”, over-extending developers and security personnel for no reason. By considering the reachability of each vulnerability, teams can now create structured plans for how to address every single vulnerability in its due time.
Summary
Given the current business dynamic of ever-growing software codebases and the fact that the threat landscape is expanding in lockstep with it, organizations need to take an active approach to figuring out ways to gain control over the mess.
If you’re looking for a solution that can help with false positives and save expensive AppSec and developer time, Myrror is a code-aware supply chain security platform that delivers quick & accurate reachability analysis to your OSS dependencies – making sure you’re continuously addressing the right vulnerabilities by shining a bright light on what actually needs to be fixed.
If you want to see reachability analysis done line-by-line to understand this process better, sign up for our newsletter or follow us on LinkedIn.