Gone are the days when you drove for hours to get the best price on a specific product. Today, buyers have price comparison apps in their pockets and use price drop alerts to catch the best deals. This is all possible through price scraping- collecting pricing information from multiple sources for comparison and informed shopping.
But there is a dark side to price scraping – illegal botnets that circumvent standard defenses against unwanted web scraping. Today, an estimated 17.7% of traffic to e-commerce sites comes from “bad bots.” While not all these bad bots are used solely for price scraping, it is a typical (and concerning) use case.
So, how do these illegal bots work, and how can you stop them from hurting your business, slowing down your website, and potentially costing you a fortune in cloud computing bills?
What is price scraping?
Price scraping, often referred to as “competitive price monitoring,” is a type of content scraping that automatically extracts pricing data from e-commerce, retail, and travel websites, apps, and APIs. Competitors often employ price-scraping bots and services to automatically track and undermine competitor pricing strategies or exploit arbitrage opportunities.
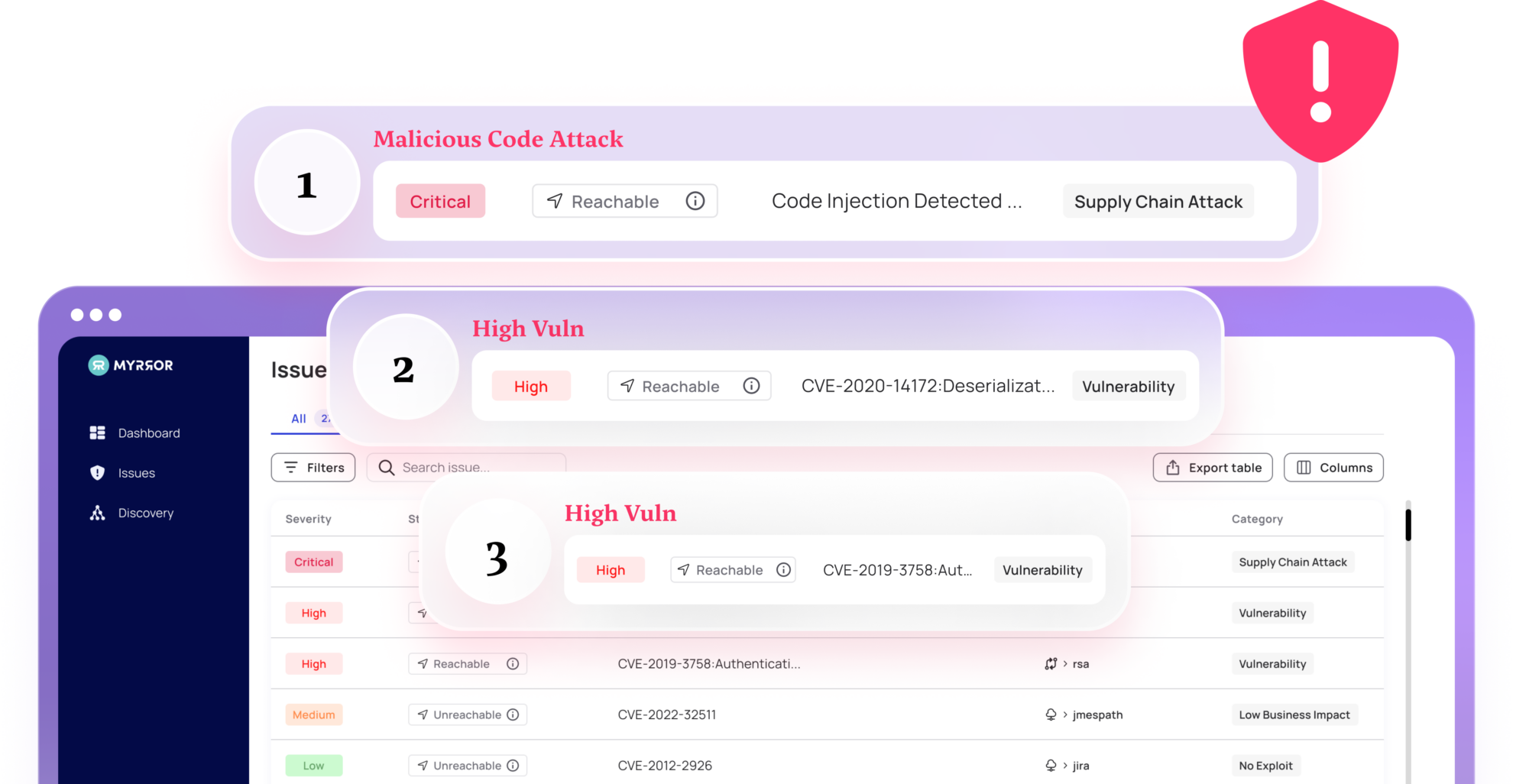
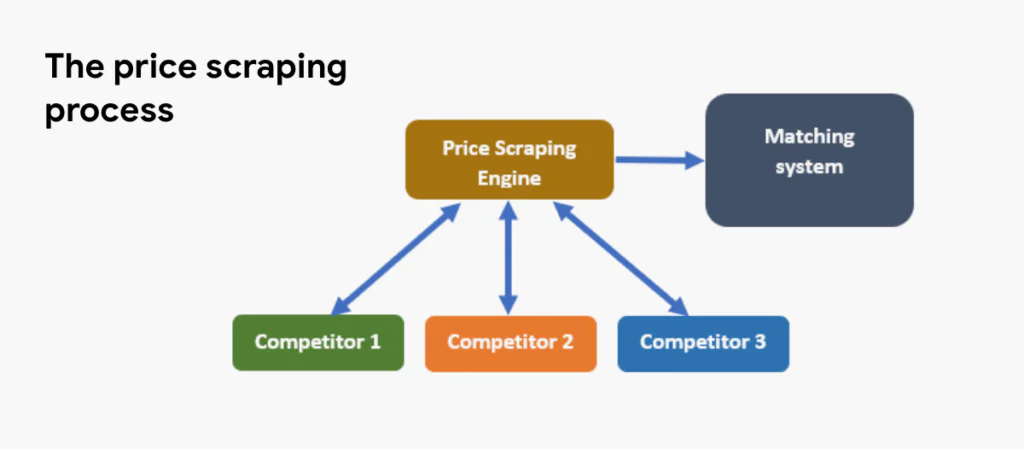
How Price Scraping Works
There are many tools and services available to perform price scraping at scale. However, the process is typically similar:
- Choosing a target website
- Extracting the relevant data using pre-set parameters and tags to recognize pricing data, including discounts, availability, shipping, and handling fees
- Storing the data in a local database or spreadsheet for resale or analysis
The complexity of a price scraping script depends heavily on the target website, and bots are becoming increasingly sophisticated at masquerading as human users to avoid detection and blocking. Some attackers may even use JavaScript injections to manipulate webpage content or alter how the data is presented, making it easier to extract pricing information without triggering typical defenses.
The most basic technique is HTML parsing, which entails programmatically scanning the code for elements that contain pricing information. When this approach is blocked, price scraping bots employ more sophisticated techniques, such as headless browsing, proxy rotation (with residential proxies), web spoofing techniques like user agent spoofing, and even sophisticated image recognition algorithms, to extract pricing information from images.
The Impacts of Price Scraping on E-commerce Businesses
Generally speaking, price scraping is not illegal as long as it is performed ethically. When the scraper identifies as such in the request header and follows your website’s robots.txt file instructions, it gives you some control over where and how the bots can scan your website. However, malicious price scraping bots don’t adhere to ethics and can cause numerous perils to any online retailer or e-commerce website administrator.
Lost Business
When it comes to low-involvement purchasing decisions, customers will abandon a shopping cart on your website when presented with a slightly better deal elsewhere. Dynamic pricing scripts and price scrapers enable automatic price matching in near real-time, allowing sellers to adjust listings in response to competitors across major marketplaces using automated repricing tools.
Degraded User Experience and Increased Infrastructure Costs
Even non-malicious price scrapers make requests to your system (and many of them). These requests can result in decreased e-commerce web performance or even downtime for genuine users, as well as a hefty additional cost to your infrastructure costs (if you use automatic scaling). Even if just 10% of the traffic to your website is bot traffic—and odds are it’s much more—that’s another 10 percent added to your cloud service vendor bills.
Inaccurate Analytics Data
The volume and quality of traffic to your website are important indicators of success in online sales. Malicious scraper bots tend to skew that data while hiding behind bogus user agent IDs and VPN IP addresses. This, in turn, can impact marketing and advertising decisions and negatively impact SEO rankings.
Brand Famage
Be it the slightly higher price or poor customer experience due to a slowed-down site, the impact of price scraping on your website can also damage your brand. No one wants to spend time and money at a slow, higher-priced online shop.
6 Tactics to Protect Your Digital Assets From Price Scraping
Many tools, scraping-as-a-service offerings, and script templates are available for price scraping (both ethical and less so). Unsurprisingly, an increasing number of tactics aim to equip developers, website administrators, and infrastructure engineers with the tools to gain better visibility and control over price scraping and other bot traffic.
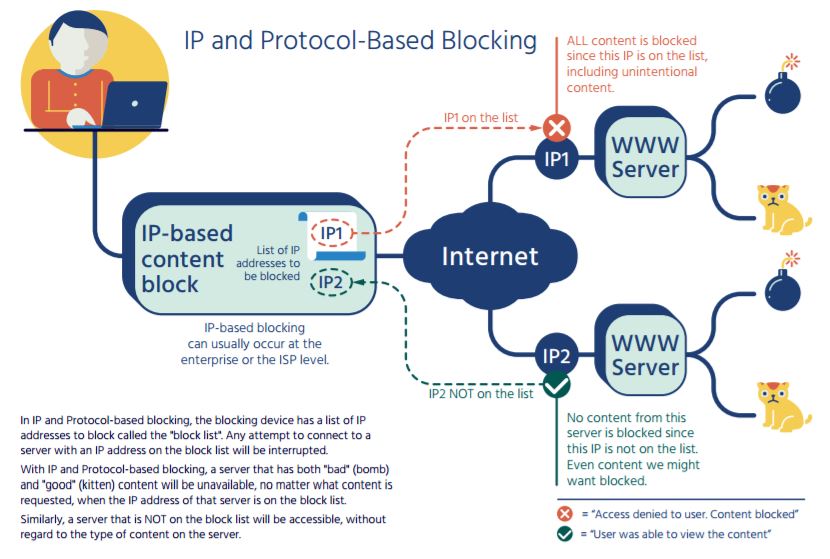
1. IP Blocking
The most common and straightforward approach to bot traffic, like price scraping, is IP address blocking at the network edge or the server level. This method automatically blocks any price scraping attempts from a specific IP address.
Alternatively, you can throttle performance for IP addresses that your risk engine marks as potentially malicious, degrading performance enough for a bot to slow down without impacting real users’ experience.
This tactic is elementary and not considered very effective on its own, as most scrapers employ VPN and proxy IP throttling to confuse your website security tools. You can, however, use it alongside other more sophisticated approaches to mitigating price scraping.
2. User-agent Filtering
When looking to block supposedly ethical bots (those that correctly report their user agent ID string), you can employ user agent filtering to disallow standard scraping tools and services from accessing your website. To do this, you must configure your server-side software to allow and disallow specific user agent strings. While relatively easy to implement, this method, much like IP filtering, is not very effective against malicious price scrapers and their sophisticated tools.
3. Session Tracking and Risk Analytics
The most critical component in your price scraping prevention strategy is gaining visibility into the true nature of the requests being made to your servers. A genuine user does not typically behave the way a bot does when browsing a website. There are clear behavioral patterns — even though malicious scrapers make significant efforts and use AI tools to mimic real user behavior.
Detecting these bad actors requires advanced analytics that correlate current and historical server logs to uncover suspicious scraping activity — ideally with the support of modern web security solutions that offer bot detection and response capabilities. By tagging devices and sessions exhibiting high-risk behavior, you can add a risk-based layer of protection against price scraping, content scraping, and other forms of automated abuse.
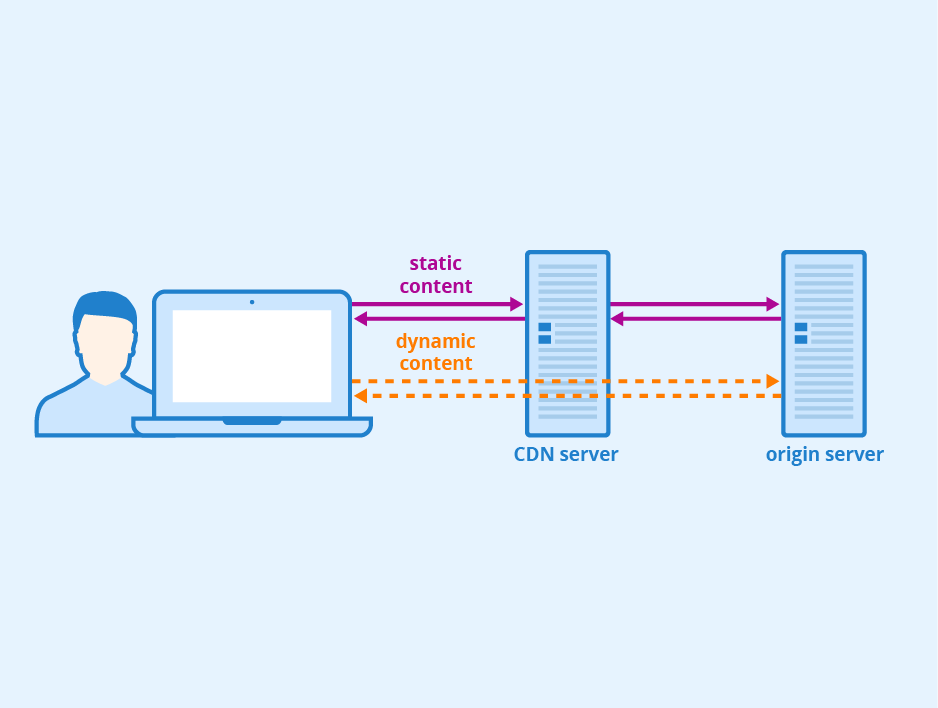
4. Dynamic Content Delivery & CDNs
In addition to server-side protection of your digital assets, you can employ techniques like dynamic content delivery to make price scraping more challenging for malicious bots. Dynamic content delivery confuses bots as to the location of pricing information in the generated HTML code.
Because the content’s structure changes with each request, bots have more difficulty finding and extracting pricing information, leading to increased costs, errors, and potential failure to extract the correct data.
Content delivery networks (CDNs) can also provide additional protection. They host some of your content protected by their anti-scraping solutions, potentially reducing the performance impact of price scraping on your website.
5. Data Obfuscation and Fake Information
Among other preventative strategies, data obfuscation can play a powerful role. This includes encrypting pricing content, altering page structure with dynamic JavaScript, or delivering misleading values to suspected bots. Feeding fake pricing data to unauthorized scrapers can confuse botnets, disrupt automated pricing strategies, and deter further scraping attempts.
While these methods can be highly effective, it’s important to carefully balance them against user experience and SEO impacts. For instance, overly aggressive obfuscation may interfere with legitimate search engine crawlers or accessibility tools.
6. Modern CAPTCHAs
One of the oldest methods of distinguishing humans from bots when accessing websites is CAPCHAs. Users are not fond of CAPTCHA (“Completely Automated Public Turing Test to Tell Computers and Humans Apart”) challenges and would rather shop elsewhere than spend time looking for buses and road signs in pictures.
That said, modern CAPTCHA solutions use behind-the-scenes user session risk analytics and additional third-party signals to minimize the number of times humans see CAPTCHAs while blocking price-scraping bots.
It’s worth noting that sophisticated price scraping operations often circumvent CAPCHAs through various tools and services, like AI-based image recognition scripts and “CAPTCHA farms” that hire cheap staffing to solve CAPTCHAs for anyone who will pay.

Detect, Deter, and Prevent Unauthorized Price Scraping
In an ideal world, retail and e-commerce site admins could control exactly which bots access which parts of their site — that’s the idea behind the robots.txt file. But in practice, anyone with basic technical skills and a scraping script can bypass those instructions.
A robust defense strategy involves combining multiple layers: user behavior analytics, session risk scoring, bot fingerprinting, and real-time response mechanisms like dynamic content delivery or honeypot data. These techniques can help you monitor and mitigate scraping activity before it affects your site performance, pricing strategy, or customer experience.