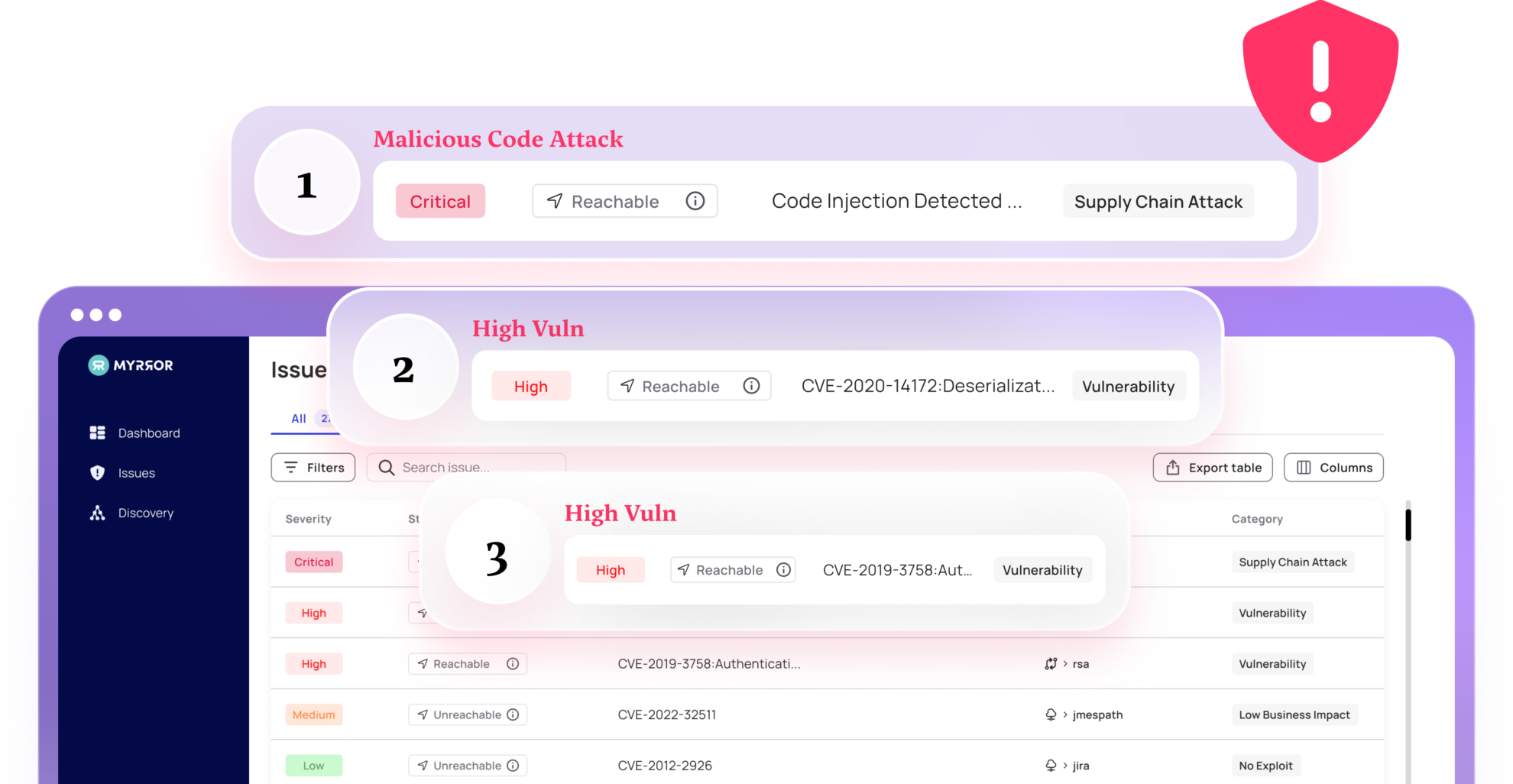
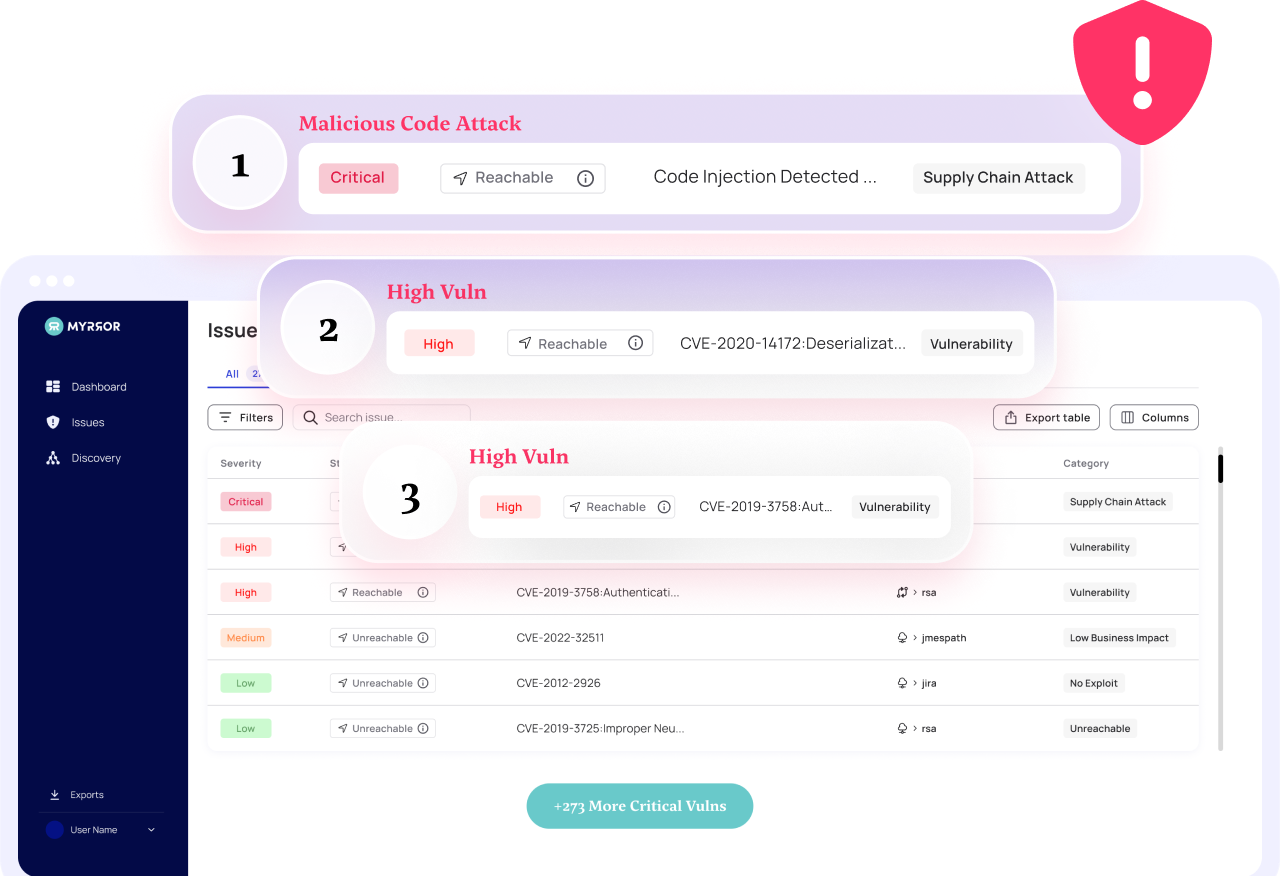
Writing secure code in today’s digital landscape is more important than ever.
Following up on the first part of Myrror Security’s Definitive Guide to Vulnerability Reachability Analysis, this piece goes into what reachability analysis looks like in practice, and how it can be used to generate prioritization of vulnerabilities for AppSec and developer teams to rely on.
As a reminder, by calculating reachability Myrror Security is able to prioritize vulnerabilities not only by their mere existence in the codebase, but also based on their actual risk of impacting your live application.
This allows developers and security teams to prioritize, plan, and patch issues that are essential and proceed with the development process while keeping aside non-impactful issues. It also allows organizations to deliver software in less time while maintaining security as per the standards that the modern software industry demands.
Let’s get started!
The Logic Behind Reachability Analysis
In the process of software development, developers often include a lot of external open-source dependencies into their applications. When the codebase grows, managing all the dependencies becomes difficult. This results in the addition of a lot of dependencies that are listed in the application’s manifest, but are not actually used in the application.
In addition, within each dependency, a lot of the functionality doesn’t get used at runtime. In some cases, they are not even present in the final application binary.
That means that when a security issue is disclosed in the dependency, the impact of that particular threat depends upon the usage of that dependency in practice.
Reachability analysis focuses on finding the impact a particular issue actually has on the provided codebase. This helps the developer be aware of the severity of the issue as well as its impact on their codebase, which reduces the notion of “alert fatigue” – developers plagued with an endless backlog of vulnerabilities, some of which highly irrelevant, to deal with.
As an example, let’s look at the way modern software is compiled. Trust us, it’s a relevant tangent!
Modern software codebases are compiled with compilers that are smart enough to exclude unused portions of the code (i.e. portions that that are never going to be part of the control flow of the application, on any possible path) in order to optimize the code execution and reduce binary size. In the end, when the application is ready to be pushed to the production environment, a lot of dependencies are not even bundled with the final version of the application.
Hence, when a security issue is found in an external open-source dependency, but calling it is part of dead code – the issue will not affect the running application, regardless of its severity.
Since the manifest file – that lists all dependencies – suggests that a dependency has been added to the application, and that a security issue is found in it, developers end up spending their time solving and patching that issue.
The following figure provides a diagrammatic explanation of the scenario:
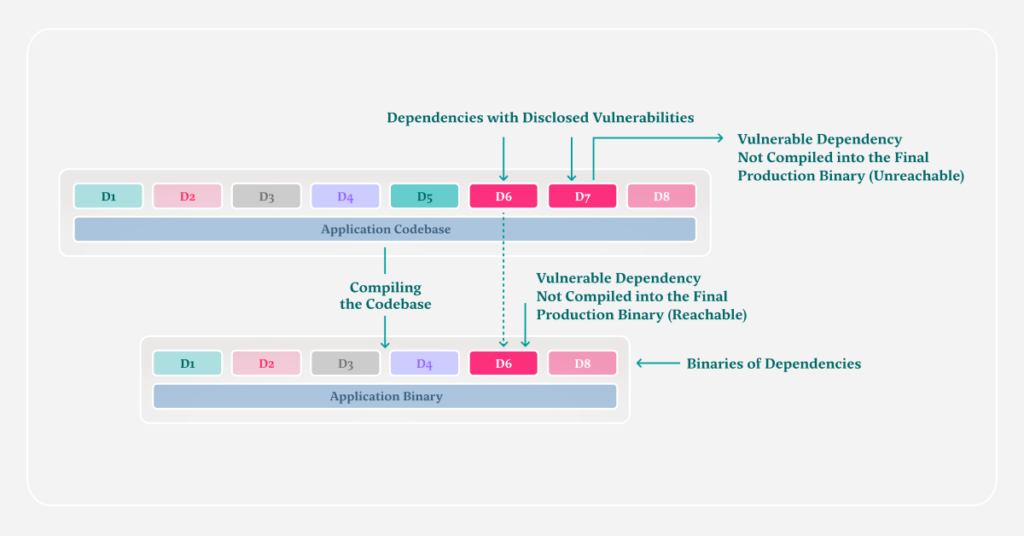
The application codebase is found to have dependencies D6 and D7 in its manifest. After the codebase is compiled for the final production build, D6 is found to be present – but D7 is not.
Hence, in the scenario of D6 and D7 being vulnerable to a critical vulnerability, only D6 would have an impact on the application’s security. D7’s vulnerability, regardless of its criticality, would not have any impact on the final production build.
Therefore, the developers need to spend time on fixing the D6 dependency first and proceed to further development – deprioritizing D7 for a later date.
If a dependency has been found to contain any security flaw, it’s essential to measure the impact of it by finding if the function is reachable by the control flow of the application.
This way, the issues in the codebase are detected and prioritized automatically, and this is the core idea behind reachability analysis.
Let’s now dive deeper into how reachability analysis is implemented in practice inside of Myrror Security’s supply chain security platform.
A Practical Implementation of Reachability Analysis
To demonstrate the way vulnerability reachability analysis works in practice, we created a version of the sshj library that contains slightly different dependencies (and vulnerabilities) for the sake of demonstration. If you haven’t heard of sshj before, it is the preferred Java option for SSH functionality. It offers a straightforward API for tasks like remote command execution, file transfers, and port forwarding.
Analyzing the application and its dependencies highlighted two main dependencies:
- BouncyCastle (Version 1.70): A Java cryptography library for secure communication and cryptographic functions, including encryption, decryption, and digital signatures.
- SnakeYAML (Version 1.33): A Java library for YAML parsing and serialization, enhancing configuration management and data exchange with customizable serialization and type-safe deserialization.
Both dependencies have security issues: BouncyCastle with a critical code injection vulnerability and SnakeYAML with a high severity improper input validation vulnerability. In addition, and as expected, both dependencies are listed in the project’s build.gradle file (which is the manifest file in the Gradle-using part of the JVM ecosystem).
Traditional SCA tools would scan this file, flag both vulnerabilities and prompt the engineering team for fixes which consume significant time. In contrast, reachability analysis delves deeper, assessing the impact more thoroughly, to decide which one of them is, in fact, vulnerable.
Myrror’s reachability analysis algorithm is static, meaning that we choose to perform the reachability analysis on the application’s source code and not dynamically, i.e., when the application is already running. Note that the exact reason why a specific dependency wouldn’t make it into the final build is not important here – the question we’re asking is boolean: is the dependency reachable from anywhere in the application or not?
The Myrror Reachability Engine At Work
Step 1 – Build an AST from the Application Source Code
The process begins with a static code analysis of the application’s source code. Myrror goes through the source code of the application, mapping each of the functions and the calls between them, including calls to external libraries. This creates a graph structure, which consists of nodes connected to each other with edges.
This graph structure is an AST – an Abstract Syntax Tree – which essentially maps all the constructs in the application’s source code.
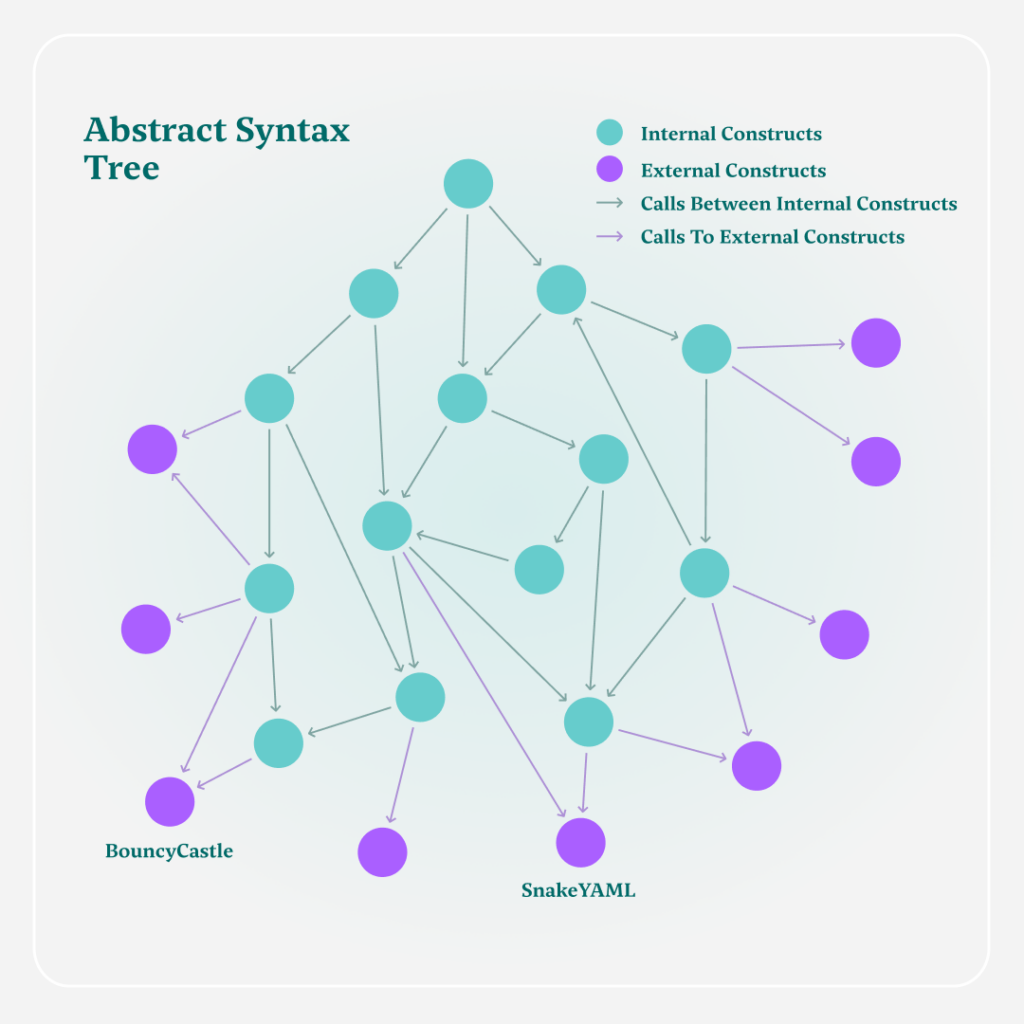
This representation provides two advantages: first we can “walk the path” between every single piece of the code to any other piece of code. In addition, we can also find parts of the code that are not connected to the rest of the code, or in our words – they’re not reachable from the main application’s codebase. This will come in handy soon when we want to detect the reachability of functions in external dependencies.
Myrror automates this graph creation process even for very large codebases which are constantly updated and keeps track of all new functions and calls to internal and external libraries. New scans, even after major changes and in multi-repo projects, happen quickly.
Step 2 – Identifying All External Calls
After the graph structure is constructed, all external calls are flagged. This means that every function call, subclasses, and the like that result in a call to an external dependency are now known to us (essentially “enumerating” every single path out of the application).
All of these external calls are entry points to dependencies – some of them vulnerable, some of them not. Now that we’ve mapped all of the dependencies, we need to figure out which one of them is actually vulnerable.
Step 3 – Find Vulnerable Dependencies
This is the stage where the manifest file is referenced – it contains a list of all dependencies this application depends on. Note that in practice, if a dependency is used but not vulnerable, we do not need to do anything else about it. Myrror knows it’s a dependency, and continuously monitors it, but there are no concrete steps to take as of yet.
Myrror now takes the manifest, finds all vulnerable dependencies, and commences the next step in the process: binary-to-source analysis of each dependency’s artifacts, in order to calculate its reachability.
Once the external dependencies are studied from the manifest file, they are collected from their respective package managers. Myrror does not consider the source code of those dependencies but focuses on the compiled binaries (the actual packages grabbed from the artifact repository).
This is done to reflect the actual process that happens during the build process – applications normally do not compile dependencies directly, they instead pull an artifact from a package manager (which means analyzing binaries provides better accuracy for analysis, instead of relying on the dependency’s source code).
Interlude – Detecting Vulnerable Functions Inside Vulnerable Dependencies
Knowing that a dependency is vulnerable just means that some portion of the dependency is vulnerable to an attack, and usually, not every single function in the package that is vulnerable is used by the application.
This means that if we can identify which parts of the package are actually vulnerable, and then check if these parts are reachable from the main application codebase (instead of just looking at the package level, like traditional SCAs), we will have much greater granularity into the effect a vulnerable package has on an application.
Myrror researchers have created an internal database that is constantly updated with public disclosures of vulnerabilities and pinpoints the exact vulnerable functions inside each vulnerability. This enables Myrror’s reachability algorithm to go beyond any other platform and find actual risks in vulnerable dependencies by using a more fine-grained approach.
Step 4 – Graphing the Execution Path of Complied Dependencies (Binary To Source Analysis)
After the packages are pulled from the artifact repository, Myrror performs its binary-to-source code analysis process and creates a graph structure of it. This graph structure is similar to the application’s codebase graph, but in fact is a CFG – a Call Function Graph – that analyzes the calls between each function in the underlying package.
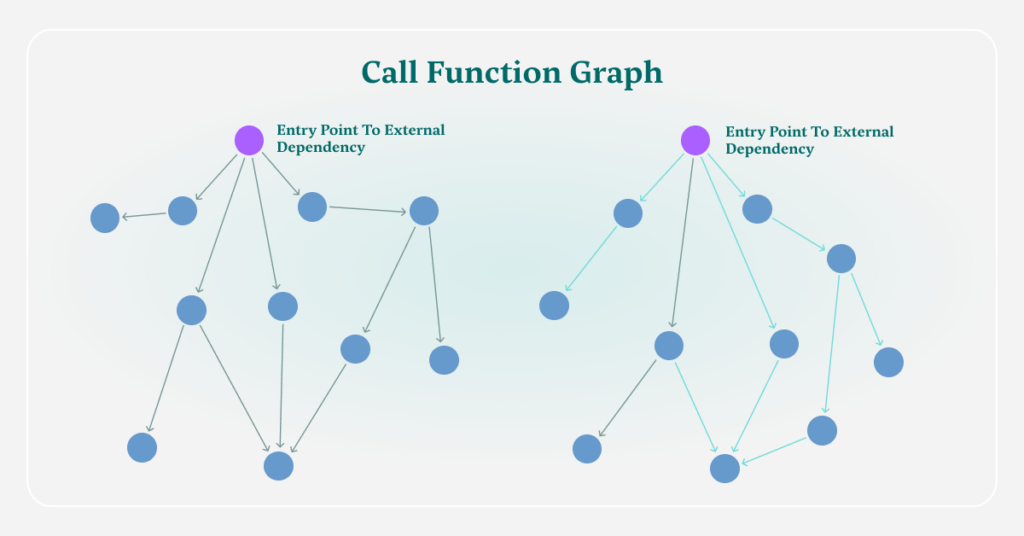
This procedure provides Myrror with graphs that contain all the possible execution paths and internal calls in the dependency. This provides a deeper dive into the suspicious dependencies, to the functional levels and allows Myrror to hunt down vulnerable functions within the dependency, facilitating the calculation of reachability.
Step 5 – Calculate Reachability Of Vulnerable Dependencies (Connecting AST to CFG)
Once the Call Function Graph is developed for a dependency, we are aware of the paths and functions inside of the dependency. With the data from Myrror’s internal database, we have very specific information about the vulnerable functions in this dependency and are ready to find paths toward them from the application codebase.
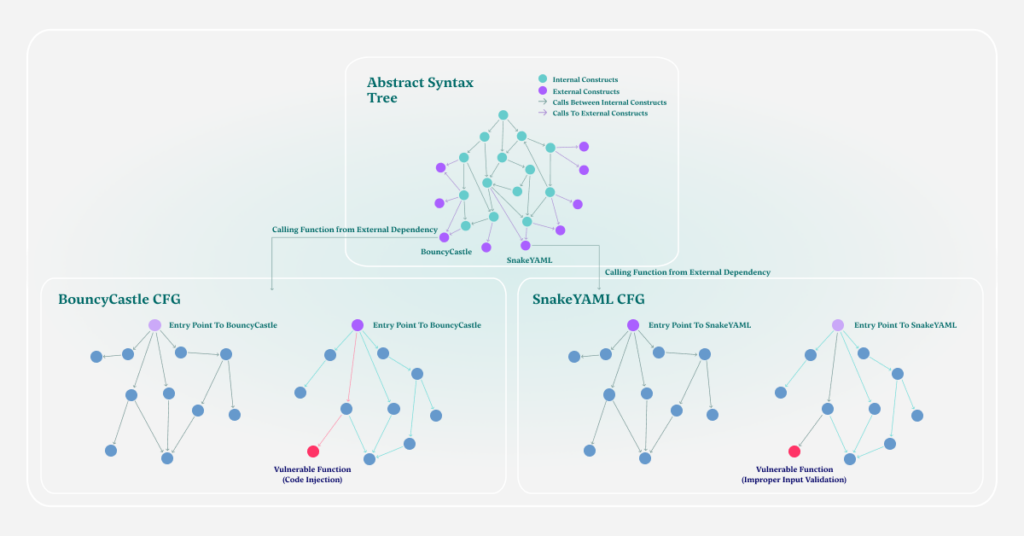
As shown in the graph, Myrror connects the original application’s AST (done using static code analysis) with each vulnerable dependency’s CFG (done using binary-to-source analysis). Myrror then goes through all the possible paths from the exit point into the dependency and traces paths toward the vulnerable functions.
After going through all possible paths toward the vulnerable functions, if one or more paths is found, the vulnerability is considered reachable. When the same procedure is carried out, and no possible paths toward the vulnerable functions are found, it’s considered unreachable.
An important note – since a dependency might depend on other several transitive dependencies, this procedure is carried out recursively for every transitive dependency as well. This process is done till the end of the call graph, both for the application codebase as well as the dependencies. This will be covered in depth in a follow-up article.
In conclusion, after the end of this process, we are left with a list of vulnerabilities & their severity, as well as their reachability – allowing us to deprioritize vulnerabilities that have no actual path towards them, and retain focus on the ones that can actually impact the application right now. This process of prioritization is very important, especially considering the alert fatigue developers face when working on very large codebases with tens of thousands of different dependencies. Myrror automates this prioritization process completely and then creates a remediation plan that allows developers to figure out what security issue to tackle at any given point in time.
Conclusion
Traditional SCAs automate threat hunting by scanning the dependencies used in the codebase, and cross-reference them with database records of publicly disclosed issues – and marking their impact on the codebase simply by the severity score of the issue.
This implementation of prioritizing issues is weak, and increases security alert fatigue. Vulnerability reachability analysis eliminates the need for developers to engage with issues that don’t impact the codebase and focus on real threats.
Myrror Security harnesses the power of reachability analysis (and exploitability analysis, tampering detection and much more) into one unified supply chain security platform, allowing organizations to continue delivering great software without getting burdened by never-ending lists of (mostly irrelevant) vulnerabilities.