It’s already been four years since the high-profile SolarWinds attack, and yet the rate of software supply chain attacks is only growing – in 2022 alone, we saw a 742% increase in open-source supply chain attacks.
In this blog post, we will discuss the types of risks that exist in the supply chain landscape, and try to divide them into two distinct categories: risks that are known and are (relatively) easy to detect, and an often-ignored category of risks we label as unknown risks.
We’ll focus more on the latter category, dive into why these so-called “unknown” risks are often left out of the security posture altogether, explain why this can be a grave mistake – and explore a few different approaches organizations can take to remediate them.
Dividing The Threat Landscape In Two
The software supply chain threat landscape is extremely dynamic; the whole concept of relying on open-source made the modern software world an ever-evolving dependency graph whose edges and nodes are continuously updated. To better understand the associated risks, we can try and divide them into two distinct categories:
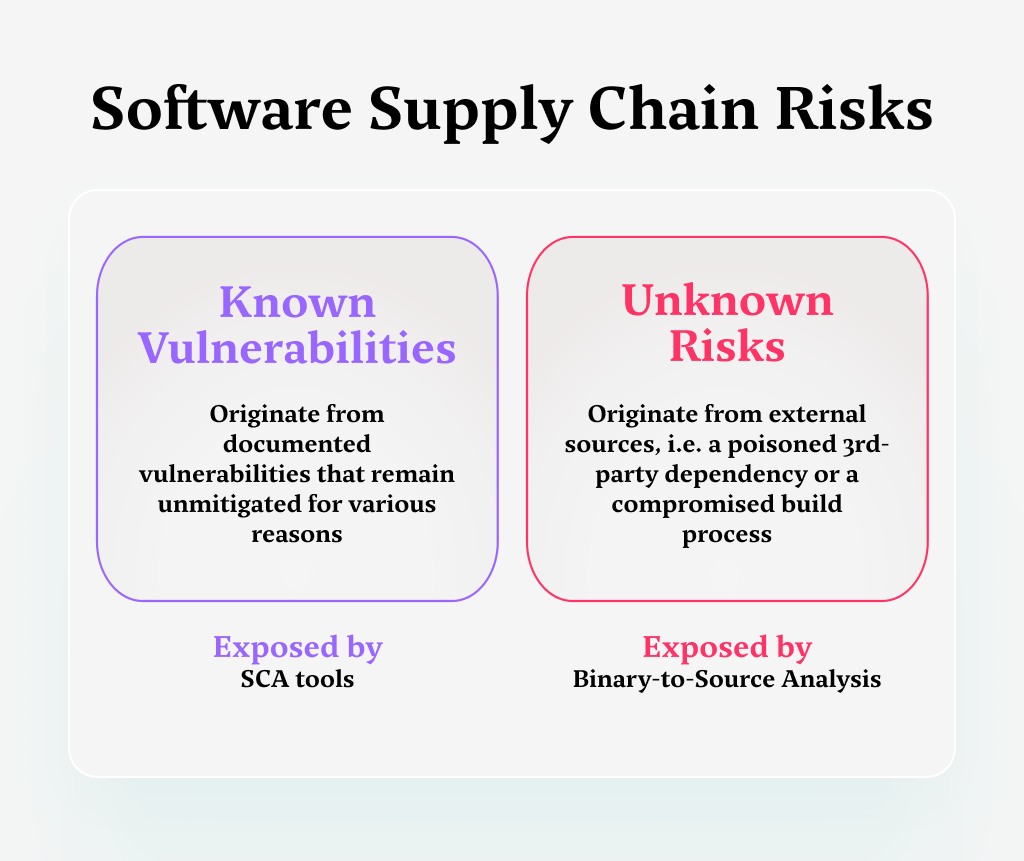
- Known vulnerabilities – These are the documented weaknesses that have been identified and typically have a remedy available. Software vendors or the cybersecurity community may already have developed and distributed patches or advised on mitigations for these vulnerabilities.
However, for various reasons, not all users have applied the fixes to address these threats. The continued exploitation of known vulnerabilities and consequential damage often stems from these inconsistent remediation management practices. - Unknown risks – These are attacks that exist in the code but originate from an external source, like a poisoned third-party open-source dependency or an attacker who compromised the build process. The result is unidentified pieces of code or logic that can be activated to execute various actions that are meant to serve the attackers’ ill intent.
Let’s start by understanding the former category, before we dive deep into the latter one and explain just how dangerous it really is.
Fighting Known Vulnerabilities in the Wild
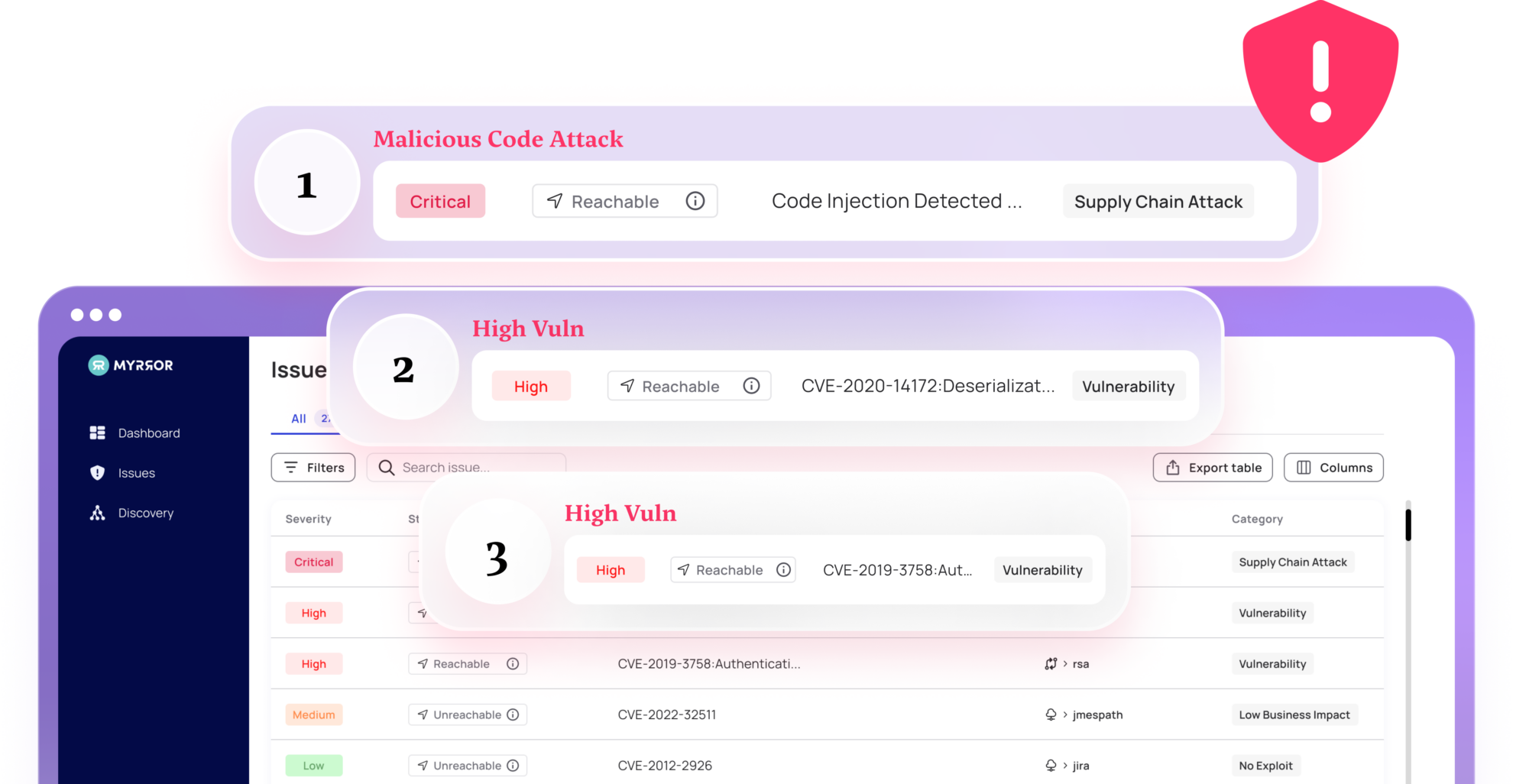
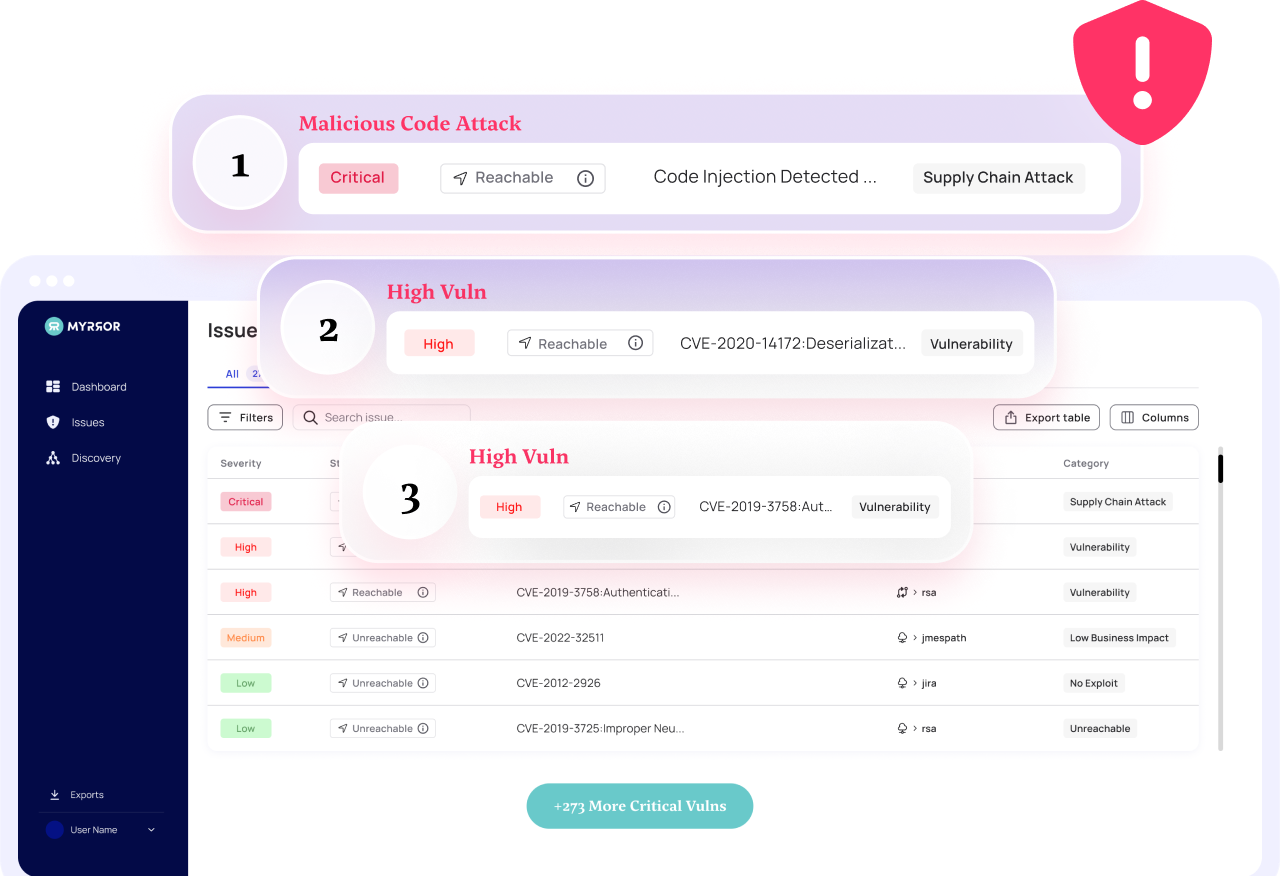
When a vulnerability is identified and reported, it usually gets stored in a public database of known vulnerabilities. Security-conscious organizations use SCA – Software Composition Analysis – platforms to track known vulnerabilities and raise a flag when one rears its head in the codebase.
SCA (Software Composition Analysis) tools scan systems for the presence of known weaknesses, particularly those for which patches and remediations are available. However, alert fatigue due to lack of a focused posture is an important issue and can be reduced by intelligent prioritization of risks.
Instead of alerting about all vulnerabilities, SCA solutions should determine whether a vulnerable function is used in the code, and only then issue a mitigation plan. This will significantly reduce the noise that is traditionally generated.
Addressing vulnerability detection through the prism of actual use represents a significant advancement, both in terms of technology and operational efficiency. Currently, SCA solutions often flag numerous potential risks, many of which are not actually reachable or exploitable in the specific context of your application.
An improved SCA solution should use a technology that employs intricate flow graphs to assess whether a vulnerable function is actively used within the application. Only if the vulnerable function is used is it flagged and alerted about to ensure it is prioritized above the unreachable and unexploitable critical ones.
This approach can dramatically reduce false positives by up to 80%, and it ensures that developers and security teams focus on genuinely relevant issues. As a result, the overall security posture is significantly enhanced, and the noise the security teams must deal with is significantly reduced, leading to more efficiency, reduced costs, and less developer and security frustration.
If possible, SCA solutions should also suggest targeted, relevant, and easy-to-understand remediation advice. This can also foster a more collaborative and efficient workflow that reduces noise and enhances the security posture.
However, for now, with the Linux Foundation estimating that open-source software constitutes 70-90% of any given piece of modern software solution – most organizations simply can’t catch up. Even with top-shelf SCAs, the burden of prioritizing and patching every single vulnerability is too much to handle for security practitioners (and the engineering teams who actually apply the patches) nowadays.
Unknown Risks Fly Under The Radar
The alert fatigue causes an undesired, dangerous side effect – any other risks, that are not publicly disclosed and easily scanned for, are often simply ignored.
Focusing solely on known vulnerabilities ignores the evolving nature of the threat landscape and attackers’ use of proactive attacks (as opposed to exploitation of self-inflicted vulnerabilities). Rather than relying on known signatures or anomalous behaviors, cybersecurity defenses also need to be dynamic and actively search for exploitable paths like poisoned 3rd-party dependencies or a compromised build process.
The main problem is that security teams and DevSecOps practitioners are simply not aware: not of the risks and not of the existence of solutions that can detect and mitigate them. Without the right technology, there is no way to be sure no additional code or logic was added between the source and the binary artifact for malicious purposes.
In addition, and as mentioned previously, they have become accustomed to looking for known software vulnerabilities, and they are operating under the incorrect assumption that by detecting those risks, their software supply chain is securely covered.
Unknown Risks Manifest In Real Life
Ignoring unknown risks is dangerous.
This is not a hypothetical risk. These are breaches that no one in the organization is aware of, and as such, they represent a blind spot in the security perimeter. They are exploitable by nature, and will be made active once you allow them into your codebase.
Not all unknown code attacks make headlines, but some do – and they do so with a bang: The 3CX breach, a trojan-horse style attack on 3CX’s CI/CD environment, resulted in hundreds of compromised customers and news of it spread through the industry. This is what happened:
After an employee installed compromised software that contained malware on their personal computer, the attacker stole the employee’s 3CX corporate credentials from his system.
Since the compromised software included a fully-featured malware that provided the attacker with administrator-level access and persistence to the compromised system, the attacker continued to move laterally through the company’s networks. During the attack, the CI/CD build environments were compromised and the attacker injected malicious code into 3CX’s desktop application, which was later downloaded by the company’s customers.
Compromising the build allowed the attackers to contaminate 3CX’s legitimate software and spread malware via the trojanized version. This not only puts 3CX at risk, but also their entire customer base – begging the question: what’s happening in the builds of open-source projects?
A Potential Solution: Protecting Packages Upstream

The prevalence of open-source software means the world is now capable of reusing software at scale; it means that a developer can use a finely-tuned, battle-tested component instead of rolling her own (however great) solution to the problem at hand.
However, with great power comes great responsibility – if entire organizations are relying on these open-source codebases, these packages should adhere to the same security standards internal codebases adhere to. Like with any other process, if the problem can be solved upstream – it will never trickle downstream and wreak havoc on a larger scale.
There are a few different ways open-source maintainers and contributors can solve this problem almost entirely on their side:
- Generating Consistent & Compliant Package Attestations provides assertions about open source software development practices at the package level, ensuring that the package is well-developed (see NIST’s TACOS as an example framework).
- Providing Reliable Package Provenance Data lets users ensure that the package comes from the correct, reputable source is a great way to reduce unknown risks (see GitHub’s support for npmjs registry provenance here, based on SLSA, as an example).
- Signing The Binary Artifacts allows users to check the file level independently (by verifying the signature) whether a package has been tampered with (see npm’s ECSDA signing procedure here, or SigStore for an example).
- Creating Reproducible Builds allows users to inspect the build process carefully, ensuring the package they use was indeed generated in the way they expect it to – minimizing the risk of the package being tampered with during the build.
But this is the utopian, ideal situation – you cannot expect this to happen in real life. What does the landscape look like in practice?
The Grim Downstream Reality
Any software developer will tell you you can’t rely on the upstream software you use to do exactly what you want it to. Sometimes you’ll have a patch waiting for weeks or months before it’s implemented – maintainers are insanely busy people, often juggling a full-time job while maintaining the package in their free time.
What can one do if the security practices mentioned above are not implemented? How can a DevSecOps practicing-organization defend itself from having its 3rd-party dependencies compromised? What can you do to ensure your build process remains squeaky clean?
The Path to a Bulletproof Secure Software Supply Chain
When it comes to unknown risks, DevSecOps teams need to think like an attacker and address the attack first. This means that two immediate things need to happen:
- Teams need to detect external malicious code and guard the build processes, to ensure the two main attack surfaces of unknown risks are accounted for.
- Once an attack has been identified, the team needs to mitigate it to avoid spreading malicious code further.
Once these two necessary steps have been completed, we can safely say we have addressed the (now known) risk and have contained it.
But how can we go about detecting risks that have never been identified, not to mention reported? How can we make sure that the packages we use are really what we expect them to be, especially in cases where the upstream security might be lacking?
Binary-to-Source Analysis: An Approach to Continuous Supply Chain Security
Adding binary-to-source code analysis capabilities to the security stack addresses the risk of unknown vulnerabilities.
This technology enables detecting trojanized packages, malicious code, and CI/CD breaches, in real-time — before they even reach production.
Binary-source validation works by inspecting build artifacts that are created during compilation, and identifying whether the artifacts or the binary outputs have been tampered with or replaced.
Such malicious components are not detectable by analyzing the source code or binaries alone. With Myrror, this binary-to-source analysis process is enhanced by AI to enable such a complex analysis process. By using binary-to-source analysis, practitioners can ensure that the packages (which they receive downstream from the package maintainers) are indeed the same packages they expect to get; even if the upstream team did not maintain their integrity there, we can ensure that they haven’t been tampered with before rolling them out to production.
Summary
To conclude, in this blog post, we’ve covered the two main pillars required to effectively address real threats in the modern software supply chain:
- Identification of code-level attacks (i.e. the detection of malicious packages and compromised build CI/CD pipelines)
- Prioritization of known vulnerabilities
We’ve also explained why DevSecOps practitioners can sometimes miss attacks resulting in 3rd-party package or build process contaminations, and the burden that lies on them due to the sheer number of known vulnerabilities that exist today.
We’ve also explored a set of possible upstream solutions to the problem, explained why they might not be possible to rely on, and presented a new approach – Binary-To-Source Analysis, which allows downstream users of the packages to ensure their integrity.